
Overview
When people think about web scraping the first language that comes to mind is Python. I thought the same too :) But while looking for a solid Go project I found out Go is actually really good at this. So I built a full RSS feed scraper with a REST API, a PostgreSQL database, a queue system to handle concurrent writes, and a React frontend to view everything.
This post covers how I built it, what problems I ran into, and what I added on top of the tutorial I followed.
I followed this YouTube tutorial to get started with the project structure and core concepts:
Key Features
- Concurrent RSS scraping using goroutines (10 feeds at the same time)
- Buffered channel queue to control how fast scraped data hits the database
- REST API with API key auth, feed management, and a follow system
- React frontend to browse articles, manage feeds, and handle account stuff
Feature Breakdown
How It Works
- User registers and gets an API key auto generated by PostgreSQL
- User adds RSS feed URLs through the API
- Every 60 seconds the scraper picks the least recently fetched feeds and hits them concurrently
- Scraped articles get pushed into a buffered channel queue
- A pool of 3 DB workers drains the queue and writes to PostgreSQL at a controlled rate
- Frontend fetches articles and feeds from the REST API
Tech Stack
- Backend: Go, Chi router
- Database: PostgreSQL, Goose (migrations), SQLC (codegen)
- Frontend: React, Vite, TypeScript (built with AI)
- Auth: API key via
Authorizationheader
go-web-scraper/
├── frontend/
│ ├── public/
│ └── src/
│ ├── assets/
│ └── pages/
├── internal/
│ ├── auth/
│ └── database/
├── scraper/
│ ├── cmd/
│ ├── models/
│ ├── router/
│ └── utils/
└── sql/
├── queries/
└── schema/The Database Setup
I used Goose for migrations and SQLC for generating Go code from SQL. Together they make database work in Go really clean.
Goose
Instead of manually running ALTER TABLE or whatever, you create versioned migration files. Goose runs them in order and tracks what has been applied.
-- +goose Up
CREATE TABLE users (
id UUID PRIMARY KEY,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
name TEXT NOT NULL,
api_key VARCHAR(64) UNIQUE NOT NULL DEFAULT (
encode(sha256(random()::text::bytea), 'hex')
)
);
-- +goose Down
DROP TABLE users;The api_key gets auto generated by PostgreSQL itself using sha256(random()) so we do not have to generate it in Go code. Run goose up to apply, goose down to roll back. Simple.
Posts table where all scraped articles live:
-- +goose Up
CREATE TABLE posts (
id UUID PRIMARY KEY,
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
title TEXT NOT NULL,
url TEXT NOT NULL UNIQUE,
description TEXT,
published_at TIMESTAMP,
feed_id UUID NOT NULL REFERENCES feeds(id) ON DELETE CASCADE
);
-- +goose Down
DROP TABLE posts;url TEXT NOT NULL UNIQUE is important. That is how duplicate articles get silently skipped without crashing.
SQLC
Write SQL queries in .sql files with a comment annotation, run sqlc generate, and it produces type-safe Go structs and functions automatically. You never touch rows.Scan(...) by hand :)
-- name: CreatePost :exec
INSERT INTO posts (id, created_at, updated_at, title, url, description, published_at, feed_id)
VALUES ($1, $2, $3, $4, $5, $6, $7, $8)
ON CONFLICT (url) DO NOTHING;
-- name: GetPosts :many
SELECT * FROM posts
ORDER BY published_at DESC NULLS LAST
LIMIT $1 OFFSET $2;SQLC gives you a CreatePost(ctx, params) and GetPosts(ctx, params) with proper Go types generated from these two queries.
The Scraper
Every 60 seconds we grab the N least recently fetched feeds from the DB and scrape them all at the same time with goroutines:
func StartScrapping(db *database.Queries, queue *PostQueue, concurrency int, timeBetweenRequest time.Duration) {
ticker := time.NewTicker(timeBetweenRequest)
for ; ; <-ticker.C {
feeds, err := db.GetNextFeedtoFetch(context.Background(), int32(concurrency))
if err != nil {
log.Println("error fetching feeds:", err)
continue
}
wg := &sync.WaitGroup{}
for _, feed := range feeds {
wg.Add(1)
go scrapefeed(db, wg, queue, feed)
}
wg.Wait()
}
}Each goroutine marks the feed as fetched, hits the RSS URL, parses the XML, and pushes each article into the queue:
func scrapefeed(db *database.Queries, wg *sync.WaitGroup, queue *PostQueue, feed database.Feed) {
defer wg.Done()
_, err := db.MarkFeedAsFetched(context.Background(), feed.ID)
if err != nil {
log.Println(err)
return
}
rssFeed, err := UrlToFeed(feed.Url)
if err != nil {
log.Println(err)
return
}
for _, item := range rssFeed.Channel.Items {
queue.Push(PostJob{Item: item, FeedID: feed.ID})
}
log.Printf("feed %q: queued %d items", feed.Name, len(rssFeed.Channel.Items))
}RSS parsing uses Go's encoding/xml. You just define structs that match the XML shape and it maps automatically, no external library needed:
type RSSFeed struct {
Channel RSSChannel `xml:"channel"`
}
type RSSChannel struct {
Title string `xml:"title"`
Link string `xml:"link"`
Description string `xml:"description"`
Language string `xml:"language"`
Items []RSSItem `xml:"item"`
}
type RSSItem struct {
Title string `xml:"title"`
Link string `xml:"link"`
Description string `xml:"description"`
PubDate string `xml:"pubDate"`
GUID string `xml:"guid"`
}The Queue
This is the part I added myself on top of the tutorial. The problem is: 10 goroutines can all finish scraping at the same time and suddenly try to write 300+ articles into PostgreSQL simultaneously. Not great for the DB :(
The solution is a buffered channel queue. Scrapers push items in as fast as they want, a small pool of workers drains it at a controlled pace.
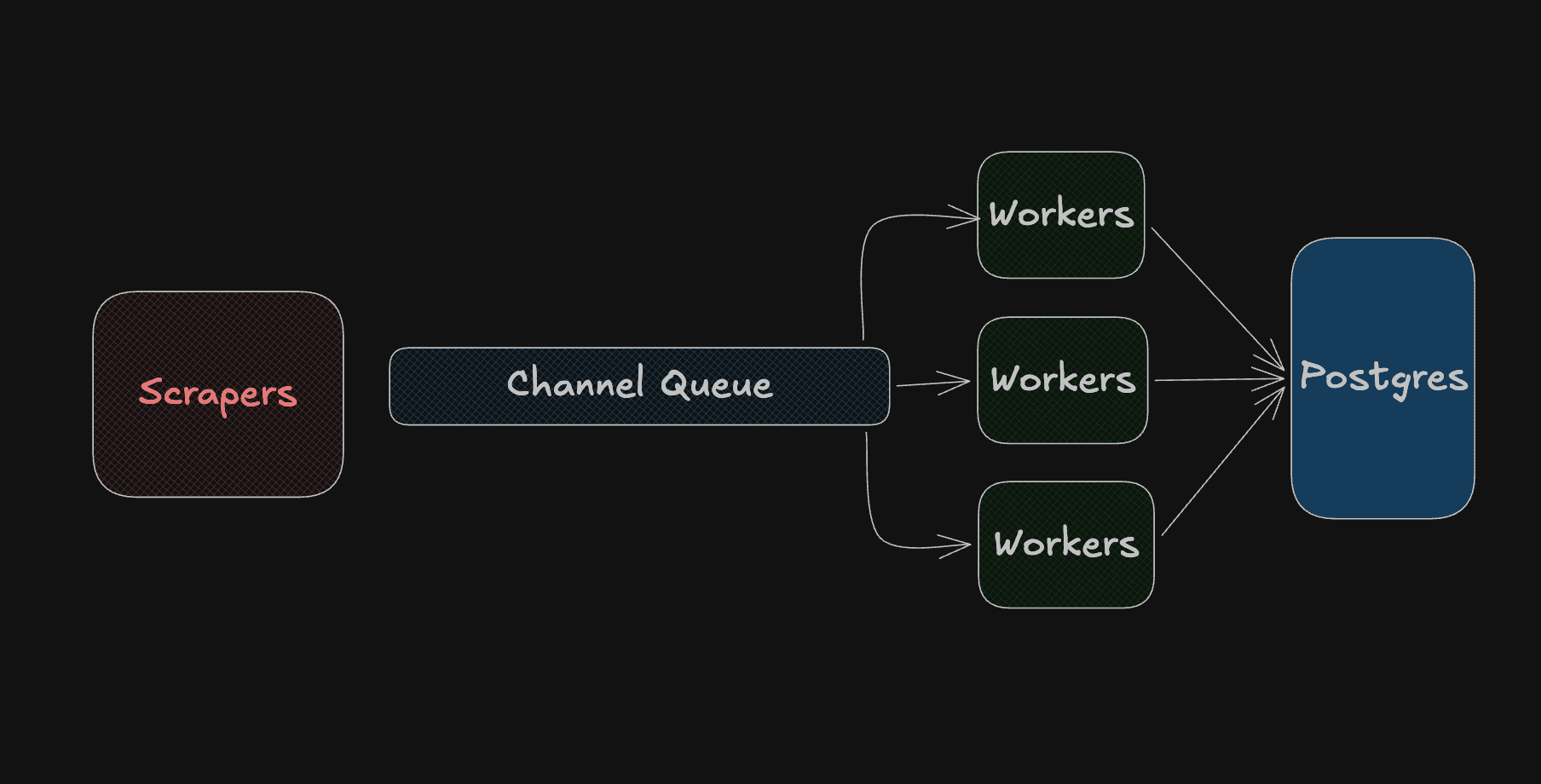
type PostJob struct {
Item RSSItem
FeedID uuid.UUID
}
type PostQueue struct {
ch chan PostJob
}
func NewPostQueue(bufferSize int) *PostQueue {
return &PostQueue{
ch: make(chan PostJob, bufferSize),
}
}Push is non-blocking. If the buffer is full the item gets dropped and logged rather than stalling a scraper goroutine:
func (q *PostQueue) Push(job PostJob) {
select {
case q.ch <- job:
default:
log.Printf("post queue full – dropping item: %s", job.Item.Link)
}
}Workers drain the channel and write to the DB with a configurable delay:
func (q *PostQueue) worker(db *database.Queries, writeDelay time.Duration) {
for job := range q.ch {
savePost(db, job)
if writeDelay > 0 {
time.Sleep(writeDelay)
}
}
}Wiring it up in main.go:
postQueue := NewPostQueue(1000)
postQueue.StartWorkers(queries, 3, 100*time.Millisecond)
go StartScrapping(queries, postQueue, 10, 60*time.Second)Classic producer-consumer pattern. Scrapers are producers, DB workers are consumers, the buffered channel is the queue in between. Go channels are literally built for this, no mutex, no external library needed.
The Frontend
I am not going to pretend I hand-wrote the React frontend. I used AI to generate it. The Go backend, the database design, the scraper, the queue were all written by me. The frontend I described what I wanted and let AI scaffold it :)
It is a React + Vite + TypeScript app. Vite proxies /api/v1/* to the Go backend so no CORS setup is needed in dev:
export default defineConfig({
plugins: [react()],
server: {
proxy: {
'/api': {
target: 'http://localhost:8000',
changeOrigin: true,
},
},
},
})Challenges And Fixes
Challenge: sql: no rows in result set error when saving posts.
I originally used :one with RETURNING * on the insert query. When a duplicate URL got skipped by ON CONFLICT DO NOTHING it returned no row and Go threw that error on every duplicate.
Fix: Switched the SQLC annotation from :one to :exec and removed RETURNING *. We do not need the row back, we just need the insert to happen.
Result: Duplicates get silently skipped, no errors, no crashes :)
Challenge: 502 Bad Gateway on the frontend.
The Vite proxy was pointing at localhost:8080 but the Go server was running on localhost:8000.
Fix: One line change in vite.config.ts. target: http://localhost:8000.
What I Learned
Go is genuinely great for this kind of project. The concurrency model is clean, the standard library covers most of what you need, and the type system catches mistakes before they become runtime bugs.
The SQLC + Goose combo is something I will use in every Go project going forward. Writing migrations as versioned files and getting generated type-safe DB code for free is just too good to go back from.
The queue was a fun problem to solve. When you have concurrent producers hitting a shared resource you need something in between. Go channels are literally made for this and I did not have to add a single dependency.
Next Steps
- Filter posts by followed feeds so you only see articles from feeds you actually care about
- Full text search on posts
- Mark as read and bookmarks
- Show last scrape error per feed in the UI so you know which feeds are broken
GitHub: go-web-scraper
Thank you for reading :D If you have any questions feel free to reach out!